
Fedora Magazine
Guides, information, and news about the Fedora operating system for users, developers, system administrators, and community members.
Updated: 2 days 6 hours ago
Contribute at Passkey Auth, Fedora CoreOS and IoT Test Week
Fedora test days are events where anyone can help make certain that changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed to Fedora Linux before, this is a perfect way to get started.
There are several test periods in the upcoming weeks.
- Thursday 21 September and Friday 22 September, is to test Passkey Auth.
- Sunday 24 September through Sunday 01 October, is to test Fedora IoT Edition.
- Monday 25 September through Monday October 02, focuses on testing Fedora CoreOS .
Passwordless authentication methods to log into Linux systems became a hot topic in the past few years. Various organizations started to mandate more secure methods of authentication, including governments and regulated industries. FIDO2 tokens, and smartcards, represent two passwordless authentication methods mandated by the US government in their Zero Trust architecture.
FreeIPA, and SSSD in Fedora 39, enable the capability to log-in to a desktop or a console terminal with a FIDO2-compatible device, for centrally managed users enrolled in Active Directory. This is supported by the libfido2 library. Additionally, for FreeIPA, once the user is authenticated with the FIDO2-compatible device, a Kerberos ticket may be issued .
As a part of this changeset , we will be having test days on Thursday 21 September and Friday 22 September. The idea is to run through test cases and submit results here.
Fedora IoTFor this test week, the focus is all-around; test all the bits that come in a Fedora IoT release as well as validate different hardware. This includes:
- Basic installation to different media
- Installing in a VM
- rpm-ostree upgrades, layering, rebasing
- Basic container manipulation with Podman.
We welcome all different types of hardware, but have a specific list of target hardware for convenience. This test week will occur Sunday 24 September through Sunday 01 October.
Fedora 39 CoreOS Test WeekThe Fedora 39 CoreOS Test Week focuses on testing FCOS based on Fedora 39. The FCOS next stream is already rebased on Fedora 38 content, which will be coming soon to testing and stable. To prepare for the content being promoted to other streams the Fedora CoreOS and QA teams have organized test days from Monday, 25 September through 2 October. Refer to the wiki page for links to the test cases and materials you’ll need to participate. The FCOS and QA team will meet and communicate with the community in async over multiple matrix/element channels. The announcements will be made 48 hours prior to the start of test week. Stay tuned to official Fedora channels for more info.
How do test days work?Test days or weeks are an event where anyone can help make certain that changes in Fedora work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. Test days are the perfect way to start contributing if you not in the past.
The only requirement to get started is the ability to download test materials (which include some large files) and then read and follow directions step by step.
Detailed information about all the test days are on the wiki page links provided above. If you are available on or around the days of the events, please do some testing and report your results.
Quick Fedora shirt update and sale of last stock with the old logo
There are some updates on Fedora shirts and sweatshirts.
Two years after the announcement of the current Fedora logo, we decided to clear our stock of shirts with the old logo. Soon our shirts will only be made and stocked with the new Fedora logo.
The Fedora jackets and hoodies are back again:
The old Fedora polo shirts are almost out of stock, so we have a new type with black buttons:
We have improved delivery too. No more taxes and customs paperwork within the European Union, the United States and the United Kingdom.
If you have your own embroidery machine, the PES file for the Fedora embroidery is available here; for the Fedora Classic, here.
Check out the embroidered Fedora collection here and don’t forget to use the FEDORA5 coupon code, for the $5 discount on every Fedora shirt and sweatshirt.
When ordering, note that the old logo style items are labelled “Fedora Classic”.
Contribute at the Fedora Linux Test Week for Kernel 6.5 and Toolbx Test Day
Fedora test days are events where anyone can help make sure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed to Fedora Linux before, this is a perfect way to get started.
There are several test periods in the upcoming weeks. Here are the first two:
- Sunday 10 Sept through Sunday 17 Sept , is to test Kernel 6.5.
- Thursday 14 Sept focuses on testing Toolbx .
The kernel team is working on final integration for Linux kernel 6.5. This recently released version, will arrive soon in Fedora Linux. As a result, the Fedora Linux kernel and QA teams have organized a test week from Sunday, Sept 10, 2023 to Sunday, Sept 17, 2023. This wiki page contains links to the test images you’ll need to participate. This is also going to be the release Kernel for Fedora 39 and any help testing regression for this Kernel will be very helpful.
ToolbxRecently, Toolbx has been made a release-blocking deliverable and now has release-blocking test criteria. Given Toolbx is very popular and has a variety of usage, we would like to run a test day to ensure nothing is broken. This test day encourages people to use containers, run apps in them ; across all platforms ie
Workstation , KDE , Silverblue and CoreOS. The details are available on this wiki and results can be submitted in the events page.
A test day is an event where anyone can help make sure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
To contribute, you only need to be able to download test materials (which include some large files) and then read and follow directions step by step.
Detailed information about all the test days is available on the wiki pages mentioned above. If you’re available on or around the days of the events, please do some testing and report your results. All the test day pages receive some final touches which complete about 24 hrs before the test day begins. We urge you to be patient about resources that are, in most cases, uploaded hours before the test day starts.
Come and test with us to make the upcoming Fedora Linux 39 even better.
Fedora libostree Post-Installation Setup, Modifications, and Tips and Tricks
What is Fedora libostree (Silverblue/Kinoite/Sericia)?
Fedora Linux’s libostree variants such as Fedora Silverblue (GNOME desktop environment) and Fedora Kinoite (KDE desktop environment) as well as Fedora Sericia (Sway window manager) are new variants of Fedora Linux that use the rpm-ostree command to perform atomic upgrades.
Consider a normal Fedora Linux installation. During an upgrade, a package manager such as DNF grabs the packages, combines them then installs them on your system. A libostree or “image-based” OS, on the other hand, is an immutable system. It fetches the image and “layers” it on top of the current one during an upgrade, providing more robust and reliable system upgrades.
“It is immutable, you can’t change it tho?” No, there are parts and workarounds that you can use to change your system in a way that you desire. Although it is not as customizable as Fedora Workstation. Hence, this article provides a comprehensive description and methods of modifications and setup that you can do in your Fedora Silverblue for optimization and some changes that you can do.
NotesI highly suggest avoiding layering as much as possible to the system image. Furthermore, I encourage you to read the information above the command first before execution. Moreover, I also suggest not rebooting unless said so, since this will make the process lengthy as opposed to how long it should be.
It is also noted that not every step is necessary, although it can be beneficial or may be some use later. I also highly recommend the cheatsheet that Fedora’s Team Silverblue provided, which you can get here:
silverblue-cheatsheetDownloadYou can also obtain the files and scripts in my GitHub repo here.
First libostree Post-Installation TasksThere are some basic tasks that you should do after the first boot.
System UpdateAfter installation, you may have an outdated system, depending on how far you were from the current release, so the first thing to do is to upgrade the system:
flatpak upgradeFlatpaks are updated first since GNOME Software automatically calls rpm-ostree upgrade after booting up. Although you can check the upgrades with:
rpm-ostree upgrade --checkor
rpm-ostree upgrade --preview Mount External DrivesIf you have an external drive, you can mount it with:
sudo mount /dev/sdX <dir>You can find the drive using lsblk or fdisk -l
If you want to automatically mount the drives on boot, you can modify /etc/fstab you will need the UUID of the device and its mount point (<dir>), you can find the UUID with lsblk -f. Then you can include the new entry to fstab with a format of:
UUID=<uuid> [TAB] <dir> [TAB] <filesystem_format> [SPACE] <options> [SPACE] <dump> [SPACE] <fsck>Here, I suggest using defaults for options, 0 for dump and fsck to disable the checking during boot to avoid increasing the boot time and potential errors upon failure of the drive. For further information, ArchWiki provides comprehensive fstab documentation. Be sure to input the correct UUID or your system might not boot.
Third-Party Repositories Flatpak SetupFedora has its own Flatpak repository where it filters some of the applications, hence, I suggest installing Flathub which comes with more applications including the proprietary ones:
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepoAfer this, do the first reboot.
Reinstalling Versioned Third-Party RepositoriesVersioned third party repository packages that rely on a given Fedora release can cause a problem during a major version upgrade, hence I recommend to replace it with a non-versioned ones.
rpm-ostree update --uninstall <versioned-third-party-repo> --uninstall <versioned-third-party-repo> --install <unversioned-third-party-repo> --install <unversioned-third-party-repo>You can include as many –uninstall <versioned-third-party-repo> and –install <unversioned-third-party-repo> as needed. Then do the second reboot.
Codecs and Drivers OpenH264 or ffmpeg-libsFedora disables the automatic install of openh264 by default, for this reason:
Upstream Firefox versions download and install the OpenH264 plugin by default automatically. Due to it’s binary nature, Fedora disables this automatic download.
https://fedoraproject.org/wiki/OpenH264But you can still install it manually with:
rpm-ostree install mozilla-openh264 gstreamer1-plugin-openh264Upon reboot, open Firefox and press Ctrl + Shift + A then enable the OpenH264 Plugins.
Flatpak ModificationsFlatpaks are sandboxed and they may not work as expected. These are some solutions to the errors that might arise.
Theming on libostree systemsSince Flatpaks are sandboxed, they cannot access the GTK theme you’ve installed in your system. One solution is to install the Flatpak version of the GTK theme you are using, which you can find with:
flatpak search gtk3Or override the themes directory which depends on how the theme was installed:
# choose one, you can do all of them but I don't recommend doing it # if installed in home dir sudo flatpak override --system --filesystem=$HOME/.themes # if installed in home dir # if layered in your system sudo flatpak override --system --filesystem=/usr/share/themes # or whatever sudo flatpak override --system --filesystem=xdg-data/themes Permissions on libostree systemsAs another Reddit user (u/IceOleg) suggested, you can disable the access to home and host dir with:
flatpak override --user --nofilesystem=home flatpak override --user --nofilesystem=hostThe home and host directories can be given back to some applications that might need it later on. Managing Flatpak permissions in the command line can be tedious. Hence, I and u/GunnarRoxen recommend installing Flatseal, which is a good utility for managing permissions:
flatpak install flathub com.github.tchx84.FlatsealIf you do not want all of the modifications made, you can reset the changes with:
sudo flatpak override --system --resetYou can also remove the ‐‐system flag and use ‐‐user instead for user-wide changes, but in this case do not use sudo. It is also possible to reset changes for a specific app with:
flatpak override --reset <app> Theming ExtendedIn some cases where themes do not apply (especially GTK4), you can force it by including it in $HOME/.profile and in the settings (settings.ini):
Do not copy and execute the below command. Replace <theme_name> with the name of the theme. One of the things I’ve learned is to not mindlessly copy and paste commands from the internet, especially long and suspicious commands.
echo "export GTK_THEME=<theme_name>" >> $HOME/.profile; if [ ! -d $HOME/.config/environment.d/ ]; then mkdir -p $HOME/.config/environment.d/; fi; echo "GTK_THEME=<theme-name>" >> $HOME/.config/environment.d/gtk_theme.conf; echo "GTK_THEME=<theme-name>" >> $HOME/.config/gtk-4.0/settings.ini ExplanationThe very long command above is a one-liner version of a script that will write “export GTK_THEME=theme_name” to $HOME/.profile:
echo "export GTK_THEME=<theme-name>" >> $HOME/.profileThen create $HOME/.config/environment.d/gtk_theme.conf file:
if [ ! -d $HOME/.config/environment.d/ ]; then mkdir -p $HOME/.config/environment.d/ fi echo "GTK_THEME=<theme_name>" >> $HOME/.config/environment.d/gtk_theme.confAnd append “GTK_THEME=<theme_name>” at the end of the gtk_theme.conf. And finally, append GTK_THEME=<theme_name> to settings.ini config.
Extreme MethodIf all of the other methods failed, you can do this as a last resort:
sudo flatpak override --system --env=GTK_THEME='<theme_name>' libostree System Optimizations Disabling NetworkManager-wait-online.serviceOne of the main contributors to long boot times, especially if you do not always have an internet connection, is NetworkManager-wait-online.service. It can take from 10 seconds to a minute or two, but you can also disable it since:
[The NetworkManager-wait-online] service simply waits, doing absolutely nothing, until the network is connected, and when this happens, it changes its state so that other services that depend on the network can be launched to start doing their thing.
https://askubuntu.com/questions/1018576/what-does-networkmanager-wait-online-service-do/1133545#1133545In some multi-user environments, it is part of the boot-up process that can come from the network. For this case, systemd defaults to wait for the network to come online before taking certain steps. Disabling it can decrease the boot time by at least 15 to 20 seconds or a minute:
sudo systemctl disable NetworkManager-wait-online.serviceMasking it is not recommend, since, as explained by u/chrisawi:
… wait-online services are WantedBy=network-online.target, so they do nothing unless another service explicitly pulls that target in because it can’t handle starting before the network is up. The nfs services are a typical example, see: systemctl list-dependencies ‐‐reverse network-online.target. It might be better to disable such services than to leave them potentially broken.
https://www.reddit.com/r/Fedora/comments/zkp5y4/comment/j00xfdh/?utm_source=share&utm_medium=web2x&context=3 Removing Unnecessary GNOME Flatpaks from libostree systemsNot all of the pre-installed applications are necessary thus you can safely remove some of them. You can completely remove a Flatpak with:
flatpak uninstall --system --delete-data <app>Here are some of the pre-installed Flatpaks that you can remove:
- Calculator: org.gnome.Calculator
- Calendar: org.gnome.Calendar
- Connections: org.gnome.Connections
- Contacts: org.gnome.Contacts
- PDF reader: org.gnome.Evince
- Logs: org.gnome.Logs
- Maps: org.gnome.Maps
- Weather: org.gnome.Weather
- Disk usage analyzer: org.gnome.baobab
By default, GNOME Software autostarts to invoke rpm-ostree upgrade ‐‐check which takes at least 100MB of RAM up to 900MB. You can remove it from the autostart in /etc/xdg/autostart/org.gnome.Software.desktop with:
sudo rm /etc/xdg/autostart/org.gnome.Software.desktop Disable dm-crypt workqeues for SSD user to improve performance on libostree systemsQuoting the Arch Wiki:
Solid state drive users should be aware that, by default, discarding internal read and write workqueue commands are not enabled by the device-mapper, i.e. block-devices are mounted without the no_read_workqueue and no_write_workqueue option unless you override the default.
https://wiki.archlinux.org/title/Dm-crypt/Specialties#Disable_workqueue_for_increased_solid_state_drive_(SSD)_performanceThe no_read_workqueue and no_write_workqueue flags were introduced by internal Cloudflare research Speeding up Linux disk encryption made while investigating overall encryption performance. One of the conclusions is that internal dm-crypt read and write queues decrease performance for SSD drives. While queuing disk operations makes sense for spinning drives, bypassing the queue and writing data synchronously doubled the throughput and cut the SSD drives’ IO await operations latency in half. The patches were upstreamed and are available since linux 5.9 and up [5].
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/drivers/md/dm-crypt.c?id=39d42fa96ba1b7d2544db3f8ed5da8fb0d5cb877The same changes were proposed to be the default for Fedora Silverblue (fedora-silverblue/issue-tracker#338). Although it is still open as tracked in Redhat’s Bugzilla, it also has been the default in Linux zen-kernel since this commit.
There are two ways to disable this in Fedora Silverblue:
Option A: /ETC/CRYPTTABI do not recommend this method, but if you want to use this, you can change the “discard” in /etc/crypttab with no-read-workqueue,no-write-workqueue. The output of sudo cat /etc/crypttab should look like this:
luks-UUID UUID=<uuid> none no-read-workqueue,no-write-workqueueThen do the fourth reboot.
Option B: CryptsetupFedora Linux uses LUKS2, hence I recommend using cryptsetup. To begin, find the device with lsblk -p, the one with the name of /dev/mapper/luks-<uuid> is the one encrypted, for example:
❯ lsblk -p NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS /dev/zram0 252:0 0 7.5G 0 disk [SWAP] /dev/nvme0n1 259:0 0 476.9G 0 disk ├─/dev/nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─/dev/nvme0n1p2 259:2 0 1G 0 part /boot └─/dev/nvme0n1p3 259:3 0 475.4G 0 part └─/dev/mapper/luks-<uuid> 253:0 0 475.3G 0 crypt /var/home ...In my case it is the /dev/nvme0n1p3. Then verify it with:
sudo cryptsetup isLuks /dev/<device> && echo SUCCESSWhere <device> is the device name, e.g. nvme0n1p3, if it echoed success then the device is encrypted. Then get the name of the encrypted device with:
sudo dmsetup info luks-<uuid>Which should output something like this:
❯ sudo dmsetup info luks-e88105e1-690f-423e-a168-a9f9a2e613e9 Name: luks-e88105e1-690f-423e-a168-a9f9a2e613e9 State: ACTIVE Read Ahead: 256 Tables present: LIVE Open count: 1 Event number: 0 Major, minor: 253, 0 Number of targets: 1 UUID: CRYPT-LUKS2-e88105e1690f423ea168a9f9a2e613e9-luks-e88105e1-690f-423e-a168-a9f9a2e613e9Note that my UUID will be different from your UUID. Take the name, in this case, luks-e88105e1-690f-423e-a168-a9f9a2e613e9, and execute the command:
sudo cryptsetup --perf-no_read_workqueue --perf-no_write_workqueue --persistent refresh <name>Then do the fourth reboot.
Removing base image packages on libostree systemsI do not recommend this, but you can do this if you want to. Note that you need to reset your system before you can go and rebase to another version if you proceed in this step. Refer here.
u/VVine6 recommended some packages that can be removed from the base image, which includes VM host support and GNOME classic shell which can be removed with:
rpm-ostree override remove open-vm-tools-desktop open-vm-tools qemu-guest-agent spice-vdagent spice-webdavd virtualbox-guest-additions gnome-shell-extension-apps-menu gnome-classic-session gnome-shell-extension-window-list gnome-shell-extension-background-logo gnome-shell-extension-launch-new-instance gnome-shell-extension-places-menuLater on, before rebasing all of the removed packages need to be included back in which case, you can reset the overrides with:
rpm-ostree override resetThis ends the general setup and modifications, you can do the final reboot here and use your system. However, for laptop users, you can continue and proceed with the section belows which also covers installation of Fish and VSCode, as well as some neat tips.
Laptop Users Set battery threshold for laptop usersI recommend setting the battery threshold to at least 80% to decrease wear on the battery. You can do this by echoing the threshold to /sys/class/power_supply/BAT0/charge_control_end_threshold. However, this resets every reboot, so it is a good idea to make a systemd service for it or download the service here:
[Unit] Description=Set the battery charge threshold After=multi-user.target StartLimitBurst=0 [Service] Type=oneshot Restart=on-failure ExecStart=/usr/bin/env bash 'echo 80 > /sys/class/power_supply/BAT0/charge_control_end_threshold' [Install] WantedBy=multi-user.targetSave this as battery-threshold.service in /etc/systemd/system/ and enable it with:
sudo systemctl enable battery-threshold.service Keyboard backlightIn some laptops, the keyboard backlight may not work out of the box, but you can toggle it with brightnessctl. First, find the keyboard backlight in /sys/class/leds by listing the directories, it usually has a name like ::kbd_backlight/brightness which can be in one or more directories, for example, in Asus laptops it is usually named as /sys/class/leds/asus\:\:kbd_backlight/brightness, then you use brightnessctl which is already installed.
To find the current brightness:
brightnessctl --device='<device>::kbd_backlight' infoIf it is set to 0, it is disabled, in 1 it is in lowest, and as the number increment, the brightness increases. You can set the brightness by brightnessctl ‐‐device='<device>::kbd_backlight’ set 3, for example, in Asus laptops it is:
brightnessctl --device='asus::kbd_backlight' set 3You can bind the command to a key using GNOME’s default keyboard shortcut or other applications, but most of the time, keyboard backlights work out of the box.
Set suspend to deep sleepIn some laptops, the battery drains rapidly when suspended under s2idle, particularly those with Alder Lake CPUs, if this is the case you can suspend using deep sleep, although it may increase the wake time. To fix this, you can set the kernel parameters with mem_sleep_default=deep:
sudo grubby --update-kernel=ALL --args="mem_sleep_default=deep"Do a reboot, then check it with cat /sys/power/mem_sleep and should output something like this:
s2idle [deep] Customizations Use Fish as default shellWhat is Fish?
Fish (friendly interactive shell) is a smart and user-friendly command line shell that works on Linux, macOS, and other operating systems. Use it for everyday work in your terminal and for scripting. Scripts written in Fish are less cryptic than their equivalent Bash versions.
https://github.com/fish-shell/fish-shellFish comes with out-of-the-box useful features such as:
- Syntax highlighting
- Web based configuration
- Inline searchable history
- Inline autosuggestion
- Tab completion using manpage data
To install Fish:
rpm-ostree install fishThen to allow toolbox to use it:
toolbox run sudo dnf install fish Set Fish as default shellSince Fedora Linux does not include chsh in the base image of Silverblue due to its setuid root, after reboot use:
sudo usermod --shell /usr/bin/fish $USER Customize Fish (basics)Fish comes with web-based configuration which can be access with:
fish_configThis will give a GUI where you can set your prompt, color of syntax highlighting, aliases, and functions. You can also disable the welcome message:
set -U fish_greeting Tips and Tricks Contrast current modifications of configs with the defaultThis can be helpful in debugging as suggested by u/VVine6
sudo ostree admin config-diff | sort | grep -v system.controlThe output will list files as Removed, Added or Modified. The defaults are available in /usr/etc in the very same path, so to revert a modification or a removal simple copy the file over.
Miscellaneous VSCodeThere are three ways to install via Flatpak (not covered here), toolbx or layering.
Toolbx InstallationCreate a toolbx with:
toolbox createYou can specify the version or distro you want to use with -r and -d, respectively. Then go inside the toolbx and update the system:
sudo dnf updateThen import the GPG keys and create the repository for VSCode:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'Finally, update the metadata and install it with:
sudo dnf check-update && sudo dnf install code.Installation in toolbx will not provide a desktop icon, to create one:
touch $HOME/.local/share/applications/code.desktopAnd append the following lines of code:
[Desktop Entry] Type=Application Version=1.0 # you can replace the version Name=Visual Studio Code Exec=toolbox run code Icon=com.visualstudio.code Terminal=falseIf you used a toolbx with different name, change Exec to:
toolbox --container <name-of-toolbox> run code LayeringSince the filesystem is immutable, you cannot import the GPG, unless you do specific changes which are not covered here. Thus, you can only create a repository for VSCode with:
sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'Then refresh the metadata and install code with:
rpm-ostree refresh-md && rpm-ostree install code Block telemetryVSCode contains telemetry, to block some of them block some of the domains in your /etc/hosts by setting it to loopback (127.0.0.1) by appending:
127.0.0.1 dc.services.visualstudio.com 127.0.0.1 dc.trafficmanager.net 127.0.0.1 vortex.data.microsoft.com 127.0.0.1 weu-breeziest-in.cloudapp.net 127.0.0.1 mobile.events.data.microsoft.comThen in $HOME/.config/Code/User/settings.json, include:
"telemetry.telemetryLevel": "off" Conclusion and AcknowledgementsThese are some modifications that can be done for Fedora Silverblue. I greatly appreciate the Fedora community from where the other tips and tricks came from, most of my knowledge came from the large knowledge base of the community, this article was written in debt to their knowledge. You can get the scripts and the files from my repo here.
Fedora Linux Flatpak cool apps to try for September
This article introduces projects available in Flathub with installation instructions.
Flathub is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “Getting started with Flatpak“. In order to enable flathub as your flatpak provider, use the instructions on the flatpak site.
FlatsealFlatseal is a graphical utility to review and modify permissions from your Flatpak applications. This is one of the most used apps in the flatpak world, it allows you to improve security on flatpak applications. However, it needs to be used with caution because you can make your permissions be too open.
It’s very simple to use: Simply launch Flatseal, select an application, and modify its permissions. Restart the application after making the changes. If anything goes wrong just press the reset button.
You can install “Flatseal” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.tchx84.FlatsealAlso available as rpm on fedora’s repositories
RecoReco is an audio recording app that helps you recall and listen to things you listened to earlier.
Some of the features include:
- Recording sounds from both your microphone and system at the same time.
- Support formats like ALAC, FLAC, MP3, Ogg Vorbis, Opus, and WAV
- Timed recording.
- Autosaving or always-ask-where-to-save workflow.
- Saving recording when the app quits.
I used it a lot to help me record interviews for the Fedora Podcast
You can install “Reco” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.ryonakano.reco Mini TextMini Text is a very small and minimalistic text viewer with minimal editing capabilities. It’s meant as a place to edit text to be pasted, it doesn’t have saving capabilities. It uses GTK4 and it’s interface integrates nicely with GNOME.
I found this to be very useful just to keep data that I want to paste anywhere, it doesn’t have unwanted and/or unneeded rich text capabilities, just plain text with minimal editing features.
You can install “Mini Text” by clicking the install button on the web site or manually using this command:
flatpak install flathub io.github.nokse22.minitext TaggerTagger is a tag editor for those of us that still save the music locally.
Some of the features are:
- Edit tags and album art of multiple files, even across subfolders, all at once
- Support for multiple music file types (mp3, ogg, flac, wma, and wav)
- Convert filenames to tags and tags to filenames with ease
You can install “Tagger” by clicking the install button on the web site or manually using this command:
flatpak install flathub org.nickvision.taggerContribute at the Test Week for the Anaconda WebUI Installer for Fedora Workstation
The Workstation team is working on the final integration of Anaconda WebUI Installer for Fedora Linux Workstation. As a result, the Fedora Workstation Working Group and QA teams have organized a test week from Monday, Aug 28, 2023 to Monday, Sept 04, 2023. The wiki page in this article contains links to the test images you’ll need to participate. Please continue reading for details.
How does a test week work?A test week is an event where anyone can help ensure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
To contribute, you only need to be able to do the following things:
- Download test materials, which include some large files
- Read and follow directions step by step
The wiki page for the Anaconda WebUI test week has a lot of good information on what and how to test. After you’ve done some testing, you can log your results in the test day web application. If you’re available on or around the days of the event, please do some testing and report your results. We have a document which provides all the necessary steps.
Docs workshop: Virtually writing together
At the Fedora Linux 38 release party, the Docs team suggested that we take advantage of a virtual meetup to bring teamwork into documentation writing. Documentation writing shouldn’t be a solitary pursuit.
An interactive session at Flock 2023 helped exchange ideas on a collaborative way to run meetings and invite more contributions for documentation.
After months of waiting for ideas to be finalized, the Docs team is pleased to announce the workshop will begin September 2023.
If you fancy coming along, just let us know your preferred timeslot in the When-is-good scheduler by September 15 2023.
But why and how?The idea behind a virtual writing session is to combine the power of the Fedora Podcast with advocacy of writing and maintaining excellent user documentation. Here is why.
- Documentation in any free and open source software project provides reasons for users and contributors to stay loyal to the project and software.
- The Docs workshop aims to facilitate individual and collaborative work through a supportive community of documentarians.
- Documentation is more than a fix of visual presentation. We’re writing, reviewing, and deploying docs.
- In accordance with the Fedora project motto “First”, we like to try new things in toolset, automation, and UI improvement.
Building on feedback from each session, the Docs team wants to empower people to learn about templates, issue tickets, review processes, and tool chains to improve documentation for Fedora Linux users and contributors.
Program agendaA monthly agenda will be posted in Fedocal and Fosstodon (@fedora@fosstodon.org).
Track 1: Introduction and onboarding (odd months)
– What the Docs team is all about. What role will interest you?
– The types of user documentation Fedora Linux publishes
– How you can help improve Fedora Documentation.
Track 2: Skill-based workshop (even months)
– Technical review, Git workshop, AsciiDoc template and attributes
– Use of local build and preview script
– Test documentation quality
Format of Track 2
– Demo
– Try it yourself
– Q&A
If you come along to the Track 2 workshop, all you need is a Fedora account and Pagure account with your computer, preferably with Git and Podman (or Docker) installed.
In the meantime, if you have questions, feel free to drop by our Discussion forum. I’m looking forward to saying hello at our first virtual docs workshop someday in late September (the exact date depends on the when-is-good responses)! Let’s do it!
TransFLAC: Convert FLAC to lossy formats
FLAC: The Lossless Audio Compression Format
FLAC, or Free Lossless Audio Codec, is a lossless audio compression format that preserves all the original audio data. This means that FLAC files can be decoded to an identical copy of the original audio file, without any loss in quality. However, lossless compression typically results in larger file sizes than lossy compression, which is why a method to convert FLAC to lossy formats is desirable. This is where TransFLAC can help.
FLAC is a popular format for archiving digital audio files, as well as for storing music collections on home computers. It is also becoming increasingly common for music streaming services to offer FLAC as an option for high-quality audio.
For portable devices, where storage space is limited, lossy audio formats such as MP3, AAC, and OGG Vorbis are often used. These formats can achieve much smaller file sizes than lossless formats, while still providing good sound quality.
In general, FLAC is a good choice for applications where lossless audio quality is important, such as archiving, mastering, and critical listening. Lossy formats are a good choice for applications where file size is more important, such as storing music on portable devices or streaming music over the internet.
TransFLAC: Convert FLAC to lossy formatsTransFLAC is a command-line application that converts FLAC audio files to a lossy format at a specified quality level. It can keep both the FLAC and lossy libraries synchronized, either partially or fully. TransFLAC also synchronizes album art stored in the directory structure, such as cover, albumart, and folder files. You can run TransFLAC interactively in a terminal window, or you can schedule it to run automatically using applications such as cron or systemd.
The following four parameters must be specified:
- Input FLAC Directory: The directory to recursively search for FLAC audio files. The case of the directory name matters. TransFLAC will convert all FLAC audio files in the directory tree to the specified lossy codec format. The program will resolve any symlinks encountered and display the physical path.
- Output Lossy Directory: The directory to store the lossy audio files. The case of the directory name matters. The program will resolve any symlinks encountered and display the physical path.
- Lossy Codec: The codec used to convert the FLAC audio files. The case of the codec name does not matter. OPUS generally provides the best sound quality for a given file size or bitrate, and is the recommended codec.
Valid values are: OPUS | OGG | AAC | MP3 - Codec Quality: The quality preset used to encode the lossy audio files. The case of the quality name does not matter. OPUS STANDARD quality provides full bandwidth, stereo music, good audio quality approaching transparency, and is the recommended setting.
Valid values are: LOW | MEDIUM | STANDARD | HIGH | PREMIUM
TransFLAC allows for customization of certain items in the configuration. The project wiki provides additional information.
Installation on Fedora Linux:
$ sudo dnf install transflacUsing Cockpit to graphically manage systems, without installing Cockpit on them!
It probably sounds too good to be true: the ability to manage remote systems using an easy to use, intuitive graphical interface – without the need to install extra software on the remote systems, enable additional services, or make any other changes on the remote systems. This functionality, however, is now available with a combination of the recently introduced Python bridge for Cockpit and the Cockpit Client Flatpak! This allows Cockpit to manage remote systems, assuming only SSH access and that Python is installed on the remote host. Read on for more information on how this works and how to get started.
If you are not familiar with Cockpit, it is described on the project’s web site as a web-based graphical interface for servers. Cockpit is intended for everyone, especially those who are:
- new to Linux (including Windows admins)
- familiar with Linux and want an easy, graphical way to administer servers
- expert admins who mainly use other tools but want an overview on individual systems
You can easily and intuitively complete a variety of tasks from Cockpit. These including tasks such as:
- expanding the size of a filesystem
- creating a network bond
- modifying the firewall
- viewing log entries
- viewing real time and historical performance information
- managing Podman containers
- managing KVM virtual machines
and many additional tasks.
Objections to using Cockpit on systemsIn the past, I’ve heard two main objections to using Cockpit on systems:
- I don’t want to run the Cockpit web server on my systems. Additional network services like this increase the attack surface. I don’t want to open another port in the firewall. I don’t want more HTTPS certificates in my environment to manage and maintain.
- I don’t want to install additional packages on my systems. I don’t even have access to install additional packages). The more packages installed, the larger my footprint is, and the more attack surface there is. For me to install additional packages in a production environment, I have to go through a change management process, etc. What a hassle!
Let’s address these one at a time. For the first concern, you have actually had several options for connecting to Cockpit over SSH, without running the Cockpit web server, for quite some time. These options include:
- The ability to set up a bastion host, which is a host that has the Cockpit web server running on it. You can then connect to Cockpit on the bastion host using a web browser. From the Cockpit login screen on the bastion host you can use the Connect to option to specify an alternate host to login to (refer to the LoginTo cockpit.conf configuration option). Another option is to authenticate to Cockpit on the bastion host, and use the Add new host option. In either case, the bastion Cockpit host will connect to these additional remote hosts over SSH (so only the bastion host in your environment needs to be running the Cockpit web server).
- You can use the Cockpit integration available with the upstream Foreman, or downstream Red Hat Satellite, to connect to Cockpit on systems in your environment over SSH.
- You can use the Cockpit Client Flatpak, which will connect to systems over SSH.
- You can use the cockpit/ws container image. This is a containerized version of the Cockpit web server that acts as a containerized bastion host
For more information on these options, refer to the Connecting to the RHEL web console, part 1: SSH access methods blog post. This blog post focuses on the downstream RHEL web console, however, the information also applies to the upstream Cockpit available in Fedora.
This brings me to the second concern, and the main focus of this article. This is the concern that I don’t want to install additional packages on the remote systems I am managing. While there are several options for using the web console without the Cockpit web server, all of these options previously had a prerequisite that the remote systems needed to have at least the cockpit-system package installed. For example, previously if you tried to use the Cockpit Client Flatpak to connect to a remote system that didn’t have Cockpit installed, you’d see an error message stating that the remote system doesn’t have cockpit-bridge installed.
The Cockpit team has replaced the previous Cockpit bridge (implemented using C) with a new bridge written in Python. For a technical overview of the function of the Cockpit bridge, and how the new Python bridge was implemented, refer to the recent Monty Python’s Flying Cockpit DevConf presentation by Allison Karlitskaya and Martin Pitt.
This new Python bridge overcomes the previous limitation requiring Cockpit to be installed on the remote hosts.
Using the Cockpit Client FlatpakWith the Cockpit Client Flatpak application installed on a workstation, we can connect to remote systems over SSH and manage them using Cockpit.
InstallationIn the following example, I’m using a Fedora 38 workstation. Install the Cockpit Client Flatpak by simply opening the GNOME Software application and searching for Cockpit. Note that you’ll need to have Flathub enabled in GNOME Software.
Using the Cockpit ClientOnce installed, you’ll see the following when opening the Cockpit Client:
You can type in a hostname or IP address that you would like to connect to. To authenticate as a user other than the user you are currently using, you can use the user@hostname syntax. A list of recent hosts that you’ve connected to will appear, if this is not the first time using the Cockpit Client. In that case, you can simply click on a host name to reconnect
If you have SSH key based authentication setup, you’ll be logged in to the remote host using the key based authentication. With out SSH keys setup, you’ll be prompted to authenticate with a password. In either case, if it is your first time connecting to the host over SSH, you’ll be prompted to accept the host key fingerprint.
As a special case, you can log into your currently running local session by connecting to localhost, without authentication.
Once connected, you’ll see the Cockpit Overview page:
Cockpit overivew menuSelect the Terminal menu item in Cockpit to show that the remote system that I’m logged in to does not have any Cockpit packages installed:
Cockpit Terminal view Prerequisites for connecting to systems with Cockpit ClientThere are several prerequisites for utilizing Cockpit Client to connect to a remote system. If you are familiar with managing remote hosts with Ansible, you’ll likely already be familiar with the prerequisites. They are the same:
- You must have connectivity to the remote system over SSH.
- You must have a valid user account on the remote system that you can authenticate with.
- If you need the ability to complete privileged operations in Cockpit, the user account on the remote system will need sudo privileges.
If you are connecting to a remote system that doesn’t have Cockpit installed, there are a couple of additional prerequisites:
- Python 3.6 or later must be installed on the remote host. This is not usually an issue, with some exceptions, such as Fedora CoreOS which does not include Python by default.
- An older version of Cockpit Client can not be used to connect to a newer operating system version. For example, if I installed Cockpit Client on my Fedora 38 workstation today and never updated it, it may not work properly to manage a Fedora 39 or Fedora 40 server in the future.
Here are some frequently asked questions about this functionality:
Question: Cockpit is extendable via additional Applications. Which Cockpit applications are available if I use the Cockpit Client to connect to a remote system that doesn’t have Cockpit installed?
Answer: Currently, Cockpit Client includes
- cockpit-machines (virtual machine management)
- cockpit-podman (Podman container management)
- cockpit-ostree (used to manage rpm-ostree based systems)
- cockpit-storaged (storage management)
- cockpit-sosreport (for generating diagnostic reports)
- cockpit-selinux (for managing SELinux)
- cockpit-packagekit (for managing software updates)
- cockpit-networkmanager (network management)
- cockpit-kdump (kernel dump configuration)
The Cockpit team is looking for feedback on what Cockpit applications you’d like to see included in the Cockpit Client. Post a comment below with your feedback.
Question: I connected to a remote system that doesn’t have Cockpit installed, but I don’t see Virtual Machines or one of the other applications listed in the menu. I thought you just said these were included in the Cockpit Client Flatpak?
Answer: When you login to a remote system that doesn’t have Cockpit packages installed, you’ll only see the menu options for underlying functionality available on the remote system. For example, you’ll only see Virtual Machines in the Cockpit menu if the remote host has the libvirt-dbus package installed.
Question: Can Cockpit applications available in the Cockpit Client be used with locally installed Cockpit applications on the remote host? In other words, if I need a Cockpit application not included in the Cockpit Client, can I install just that single package on the remote host?
Answer: No, you cannot mix and match applications included in the Cockpit Client flatpak and those installed locally on the remote host. For a remote host that has the cockpit-bridge package installed, Cockpit Client will exclusively use the applications that are installed locally on the remote host. If the remote host does not have the cockpit-bridge package installed, Cockpit Client will exclusively use the applications bundled in the Cockpit Client Flatpak.
Question: Can I use Cockpit Client to connect to the local host?
Answer: Yes! Simply open Cockpit Client and type in localhost and you’ll be able to manage the local host. You don’t need to have any Cockpit packages installed on the local host if you use this method. You only need the Cockpit Client Flatpak.
Question: What Linux distributions can I connect to using the Cockpit Client?
Answer: Cockpit is compatible with a number of different Linux distributions. For more information, see the Running Cockpit page. If connecting to a remote system that doesn’t have Cockpit installed, keep in mind the previously mentioned requirements regarding not connecting to newer OS’s from an older Cockpit Client.
Question: Does the Cockpit team have any future plans regarding this functionality?
Answer: The Cockpit team is planning on adding the ability to connect to remote hosts without Cockpit packages installed to the cockpit-ws container image. See COCKPIT-954 ticket for more info.
Have more questions not covered here? Ask them in the comments section below!
ConclusionThe new Python bridge, and the corresponding ability to use the Cockpit Client to connect to remote systems without installing Cockpit, makes it incredibly easy to use Cockpit in almost any circumstance.
Try this out! It’s easy to do. Simply install the Cockpit Client Flatpak, and use it to connect to either your localhost or a remote system. Once you’ve tried it, let us know what you think in the comments below.
Contribute during the DNF5, GNOME 45, and i18n test days
Fedora test days are events where anyone can help make sure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed to Fedora Linux before, this is a perfect way to get started.
There are four test periods in the upcoming weeks:
- Friday 11 August through Thursday 17 August , is to test DNF5.
- Monday 14 August through Sunday 20 August, two test day periods focusing on testing GNOME Desktop and Core Apps.
- Tuesday 5 September through Monday 11 September, is to test i18n.
Come and test with us to make the upcoming Fedora Linux 39 release even better. Read more below about how to do it.
DNF5Since the brand new dnf5 package has landed in rawhide, we would like to organize a test week to get some initial feedback on it before it becomes the default. We will be testing DNF5 to iron out any rough edges.
The test week will be Friday 11 August through Thursday 17 August. The test week page is available here .
GNOME 45 test weekGNOME 45 has landed and will be part of the change for Fedora Linux 39. Since GNOME is the default desktop environment for Fedora Workstation, and thus for many Fedora users, this interface and environment merits a lot of testing. The Workstation Working Group and Fedora Quality team have decided to split the test week into two parts:
Monday 14 August through Thursday 17 August, we will be testing GNOME Desktop and Core Apps. You can find the test day page here.
Friday 18 August through Sunday 20 August, the focus will be to test GNOME Apps in general. This will be shipped by default. The test day page is here.
The i18n test week focuses on testing internationalization features in Fedora Linux.
The test week is Tuesday 5 September through Monday 11 September. The test week page is available here.
How do test days work?A test day is an event where anyone can help make sure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
To contribute, you only need to be able to download test materials (which include some large files) and then read and follow directions step by step.
Detailed information about all the test days is available on the wiki pages mentioned above. If you’re available on or around the days of the events, please do some testing and report your results. All the test day pages receive some final touches which complete about 24 hrs before the test day begins. We urge you to be patient about resources that are, in most cases, uploaded hours before the test day starts.
Come and test with us to make the upcoming Fedora Linux 39 even better.
Fedora Linux Flatpak cool apps to try for August
This article introduces projects available in Flathub with installation instructions.
Flathub is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “Getting started with Flatpak“. In order to enable flathub as your flatpak provider, use the instructions on the flatpak site.
AuthenticatorAuthenticator is a simple app that allows you to generate Two-Factor authentication codes. It has a very simple and elegant interface with support for a a lot of algorithms and methods. Some of its features are:
- Time-based/Counter-based/Steam methods support
- SHA-1/SHA-256/SHA-512 algorithms support
- QR code scanner using a camera or from a screenshot
- Lock the application with a password
- Backup/Restore from/into known applications like FreeOTP+, Aegis (encrypted / plain-text), andOTP, Google Authenticator
You can install “Authenticator” by clicking the install button on the site or manually using this command:
flatpak install flathub com.belmoussaoui.Authenticator SecretsSecrets is a password manager that integrates with GNOME. It’s easy to use and uses the KeyPass file format. Some of its features are:
- Supported Encryption Algorithms:
- AES 256-bit
- Twofish 256-bit
- ChaCha20 256-bit
- Supported Derivation algorithms:
- Argon2 KDBX4
- Argon2id KDBX4
- AES-KDF KDBX 3.1
- Create or import KeePass safes
- Add attachments to your encrypted database
- Generate cryptographically strong passwords
- Quickly search your favorite entries
- Automatic database lock during inactivity
- Support for two-factor authentication
You can install “Secrets” by clicking the install button on the site or manually using this command:
flatpak install flathub org.gnome.World.Secrets FlatsweepFlatsweep is a simple app to remove residual files after a flatpak is unistalled. It uses GTK4 and Libadwaita to provide a coherent user interface that integrates nicely with GNOME, but you can use it on any desktop environment.
You can install “Flatsweep” by clicking the install button on the site or manually using this command:
flatpak install flathub io.github.giantpinkrobots.flatsweep SolanumSolanum is a time tracking app that uses the pomodoro technique. It uses GTK4 and it’s interface integrates nicely with GNOME.
You can install “Solanum” by clicking the install button on the site or manually using this command:
flatpak install flathub org.gnome.SolanumVideo content creation with Kdenlive
Fedora Linux packages a suite of graphical software for content creators. This article introduces a use case and suggestions for creating tutorial videos with Kdenlive.
Plan tutorialA question that you need to address is whether text and images are appropriate to share your knowledge. If you create resources for learners of graphical software, a tutorial video is something to consider.
Review abstract and draft scriptAn abstract in content writing helps reviewers look for key points of your tutorial. Depending on your workflow, you can submit this abstract to reviewers for comments, questions, or updates.
Once an abstract of the tutorial video is agreed upon by the reviewers, a video script is created and works like a manuscript for your tutorial. Break down process steps into each sequence. Check this link for an example.
Screen recordingUse your preferred recording tool that comes with the desktop environment or enable the ‘Screen Grab’ option in Kdenlive in the ‘View’ menu. Alternatively, you can install OBS Studio.
Kdenlive can process various container formats. You should transcode to a high-quality lossless matroska file (.mkv) that ensures high quality and compression ratio.
InstallationKdenlive supports Linux, Mac, Windows and FreeBSD, which encourages collaboration among content creators. If you are Linux users, go to the packager manager of your distro to install Kdenlive. If you use Fedora Linux, we recommend the Fedora Linux RPM version or Flatpak.
Set up KdenliveLet’s start with Kdenlive’s user interface and focus on three sections – Project bin, Monitors and Timeline.
Kdenlive user interface Project binLoad video clips into Project Bin on the upper left. The Project Bin lists all the clips that are associated with your project. You can drag and drop the clips onto Project Bin.
MonitorsClip Monitor on the left window displays the unedited clip that is currently selected in The Project Bin. If you have loaded multiple takes of the same scene (process steps), you need to know which one you’re going to choose and edit. If you changed your mind during editing processes, that’s no problem. You can move around a sequence with timeline and tracks after the initial cut.
The Project Monitor is a place to watch your edited footage.
TimelineTimeline is a place for all selected clips you edit. Drag and drop the clips directly on to the Timeline from the Project Bin.
Editing processes Cut and stitchTimeline cursor, also known as playhead, indicates the position of clips you are working on and previewing in the Project Monitor.
Timeline
The initial cut means editing on a scene by scene basis until you’re ready to stitch tracks together into a complete piece.
Cut when;
– Delayed, boring or repetitive part was recorded. This happens often when recording a scene for loading apps or waiting for rendering on web browser
– Transition pieces when a scene starts and ends
– Trim off a few frames before you tidy up
– Ensure basic continuity – let it flow!
In Timeline, video tracks (V2, V1) are cascaded up whereas audio tracks (A1, A2) are cascaded down as default.
Slide up trimmed video track and stitch frames you want to keep. Delete trimmed frames when you’re sure you don’t need them.
Cut
Timeline works like chef’s chopping board and takes time for new users to get familiar with it. Check the upstream documentation on this link.
Text effects with TitlesTitles are text elements that you can overlay to the timeline. To create Titles, right-click in the The Project Bin and open the Titles window as shown below. Select ‘Create Title’ to save it. Drag and drop the Title to the video track 2 in timeline. Check this link for more information.
Titler Sound effectsAmbient music could jazz up your video tutorial for the audience.
Go to top left corner of the Project Bin and select the arrow to list options. Select ‘Online Resources’. At the top right, ‘Service’ drop-down menu, choose ‘Freesound’. Select ‘Preview’ to play back and import to download and overlay to A1 audio track.
Sound Transition and finishing touchText and sounds effects will blend well if tracks have transitions. Check this link for fine-tuning your final cut video.
RenderingIn the Render dialogue box (Ctrl + Return) on Project Bin, choose WebM as output file, select ‘More options’ to de-select the Export Audio option, and select ‘Render to File’ to save the clip.
Rendering
WebM offers good compression and output.
Rendering speed is dependent on the number of CPU cores in your computer. If you work with high quality footage and visual effects in a computer with low-end CPU and RAM, adapt your workflow with proxy clips and use script for rendering.
Share your tutorial videoPeerTube is a video sharing platform that runs on GNU/Linux infra, and Open Source/Free Software. Just like Vimeo or YouTube, you can embed your content to your documentation site from PeerTube.
Credits and acknowledgementsBig thanks to Seth Kenlon who provided me with a great deal of inspiration from his publication in Opensource.com and Kdenlive workshop.
Kdenlive Version 23.04.2 was used for this article.
Coming soon: Fedora for Apple Silicon Macs!
Today at Flock, we announced that Fedora Linux will soon be available on Apple Silicon Macs. Developed in close collaboration with the Fedora Asahi SIG and the Asahi Linux project, the Fedora Asahi Remix will provide a polished experience for Workstation and Server usecases on Apple Silicon systems. The Asahi Linux project has also announced that the new Asahi Linux flagship distribution will be Fedora Asahi Remix.
We are using a Remix as opposed to delivering this support in Fedora Linux proper because this ecosystem is still very fast moving and we believe a Remix will offer the best user experience for the time being. Also, the Remix will allow us to integrate hardware support as it becomes available. Nonetheless, as much of this work as possible is being conducted upstream, with several key components being developed, maintained and packaged in Fedora Linux upstream. Ultimately, we expect Apple Silicon support to be integrated in Fedora Workstation and Fedora Server in a future release, and are working towards this goal. This approach is in line with the overarching goal of the Asahi project itself to integrate support for these systems in the relevant upstream projects.
The first official release of Fedora Asahi Remix is slated to be available by the end of August 2023. Development builds are already available for testing at https://fedora-asahi-remix.org/, though they should be considered unsupported and likely to break until the official release.
Get ready to Flock to Fedora!
A letter from Fedora Project Leader Matthew Miller
Hello Fedora friends! In just about a week, we will kick off Flock to Fedora — our annual contributor conference. I hope you’re as excited as I am! For the last three years, we’ve run this as a virtual event — we stayed cozy at home with Nest. Now, we’re back to in-person, and I can’t wait to see so many of you again as we flock together to meet in Cork, Ireland.
Flock is different from other conferences — it’s not a showcase or sales pitch, and it’s not a corporate event where we stand up for or root for the companies we work for or are fans of. Of course, we are grateful for our sponsors and our employers, but in Fedora in general — and especially at Flock! — that’s not what things are about. We come together in a positive spirit to collaborate and build. We’re a community of people, and friendship is a cornerstone value. Fedora is our community, and Flock is where we come together.
This year, we’re combining forces with our friends at the CentOS Project: CentOS Connect will be co-located with Flock. CentOS is a different kind of project, but the same approach applies: this is about community. I know there are a lot of strong feelings around Red Hat and CentOS and rebuilds and downstreams lately. Fedora doesn’t control any of that, but it affects us — so, I’m sure we’ll talk about it. (We even have a session related to the topic.) As we talk, though, let’s all keep in mind the spirit of our projects: working together collaboratively to build a better world with free and open source software for everyone.
The Nest events were wonderful: the best virtual events during the whole pandemic, I think. While I obviously am biased about this, I think it’s fair, since I didn’t really do any of the organizing work. (Thanks to everyone who did, and especially to Marie Nordin!) This year, while we wish everyone could be there in person, we want to make the event as accessible as possible to those who can’t be there, so we will live-stream and record the sessions. I hope you’ll join as many sessions as your local time zone permits.
I look forward to talking about our in-progress strategy, and our goal of doubling the number of active Fedora contributors. I want to hear what all of you are working on, all the ideas you have, all the proposals and plans for the future. Most of all, though, I’m looking forward to seeing so many of my friends again, and making new connections. I hope you are too!
Be sure to check out the schedule. If you haven’t registered yet, don’t forget to do that!
How to Install and Update Fedora Linux on Android using Termux
If you’re interested in running Linux on your Android device, you’re in luck! It’s possible to install Fedora Linux on Android using Termux. Termux is a terminal emulator for Android that allows you to run Linux commands and utilities on your phone or tablet. It does not replace Android. In this article, we’ll walk you through the process of installing Fedora Linux on Android using Termux and show you how to keep it up to date with the latest versions.
Step by step processStep 1: Install Termux
To get started, you need to install Termux from the Google Play Store. Once you have Termux installed, open it up and type the following command to update the package list:
pkg updateNote: Termux requires Android >= 7 to run. Support for Android 5 and 6 was dropped at v0.83 on 2020-01-01, but you can find old builds on archive.org ( https://archive.org/details/termux-repositories-legacy/ ) if needed.
Step 2: Install Proot-Distro
Next, you’ll need to install Proot-Distro. Proot-Distro is a tool that allows you to install and run Linux distributions in a chroot environment. To install Proot-Distro, run the following command:
pkg install proot-distroStep 3: Install Fedora
With Proot-Distro installed, you can now use it to install Fedora. To install Fedora, run the following command:
proot-distro install fedoraThis will download and install the latest version of Fedora.
Step 4: Configure dnf
Now that you have Fedora installed, you’ll need to configure dnf, Fedora’s package manager. By default, dnf may try to install SELinux packages, which won’t work properly in a chroot environment. To prevent this, exclude SELinux packages installation by editing the dnf configuration file. Run the following command to open the dnf configuration file for editing :
cd ../usr/var/lib/proot-distro/installed-rootfs/fedora/etc/dnf vi dnf.confYou may substitute the nano editor for vi, if it is more to your liking. Once you’re in the file, find the line that says excludepkgs= and add *selinux* to the end of the line, like so:
excludepkgs=*selinux*It may be necessary to add the excludepkgs line. Save these changes and exit the editor.
Step 5: Install a Desktop Environment (Optional)
Fedora comes with a number of desktop environments to choose from. If you’d like to install a desktop environment, you can do so with the following commands:
proot-distro login fedora dnf groupinstall "Fedora Workstation" --skip-brokenThis will switch from termux into the chroot Fedora installation and install the GNOME desktop environment, along with a number of other packages. If you prefer a different desktop environment, you can replace Fedora Workstation with the name of the group for your preferred environment.
Step 6: Install VNC Server (Optional)
If you plan on using your Fedora installation with a graphical interface, you’ll need to install a VNC server. This will allow you to connect to the Fedora desktop from another computer or device. To install the TigerVNC server, run the following command:
dnf install tigervnc-server.aarch64 -yThis will install the VNC server, along with any necessary dependencies.
Step 7: Upgrading Fedora
Now that you have Fedora installed, you’ll want to keep it up to date with the latest versions. To upgrade Fedora, run the following commands:
sudo dnf upgrade --refresh sudo dnf install dnf-plugin-system-upgrade sudo dnf system-upgrade download –releasever=37 export DNF_SYSTEM_UPGRADE_NO_REBOOT=1 sudo -E dnf system-upgrade reboot sudo -E dnf system-upgrade upgrade sudo dnf upgrade --refreshFirst command sudo dnf upgrade –refresh refreshes the package cache and updates any installed packages.
The second command sudo dnf install dnf-plugin-system-upgrade installs the dnf-plugin-system-upgrade package, needed for the upgrade process.
The third command sudo dnf system-upgrade download –releasever=37 downloads the necessary packages for the upgrade to version 37 of Fedora. Replace 37 with the desired release version.
The fourth command export DNF_SYSTEM_UPGRADE_NO_REBOOT=1 sets an environment variable to prevent the system from rebooting after the upgrade.
The fifth command sudo -E dnf system-upgrade reboot reboots the system to start the upgrade process. Make sure to save any important work before running this command.
The sixth command sudo -E dnf system-upgrade upgrade performs the upgrade process.
Finally, the seventh command sudo dnf upgrade –refresh updates any remaining packages and ensures that your system is fully up to date.
Errors EncounteredDuring the installation and upgrade process, you may encounter errors. Two common errors are described below, along with their solutions.
Error 1: sudo: /etc/sudo.conf is owned by uid 1001, should be 0
Solution: This error occurs when the ownership of the sudo.conf file is incorrect. To fix this, run the following command:
This sets the setuid bit on the sudo command, which allows it to run with root privileges.
Error 2: filesystem package didn’t get upgraded post OS upgrade
Solution: This error occurs when the filesystem package is not upgraded during the upgrade process. To fix this, run the following commands:
The first command removes the filesystem package, and the second command downloads the latest version of the package. If you encounter any errors during the upgrade process, you can use rpmrebuild to rebuild the package with any necessary modifications.
ConclusionIn this article, we’ve shown you how to install Fedora Linux on Android using Termux and how to keep it up to date with the latest versions. While there may be some errors to overcome during the installation and upgrade process, following the steps outlined in this article should help you get Fedora up and running on your Android device in no time.
Packit – how to trigger jobs manually
Packit is an open-source project aiming to ease the integration of your project with Fedora Linux, CentOS Stream, and other distributions. Projects that use Packit usually build RPM packages. This article will introduce new features. The new user onboarding process is available here.
Testing Farm executionFrom Packit you can easily trigger your tests on Testing Farm without building the RPMs. This is very handy for projects that basically may not build RPMs, but just want to use these two services for verifying the code. As a good example, we refer to the Strimzi project where users consume container images.
In such cases, the users just want to trigger the tests, verify the code and see some output. This option is available from the beginning. Users can easily define when the tests will be executed – for every pull request, for every commit, or for releases. That sounds pretty cool. However, when you have complex tests (5h+ per test run as we have in Strimzi) you probably don’t want to trigger all tests for each commit. So how can the users achieve that?
Manual TriggerWe introduced a new configuration option, manual_trigger, to enable triggering Packit jobs only manually. With this new configuration of Packit jobs, users can easily enable the manual triggering of a job. The job will NOT automatically trigger when, for example, a new commit arrives to pull a request.
Users need to specify manual_trigger in the test’s job description. The value for this option must be boolean and will default to False. The following is an example of the use of this option. A more complete example is available here.
... - job: tests trigger: pull_request identifier: "regression-operators" targets: - centos-stream-9-x86_64 - centos-stream-9-aarch64 skip_build: true manual_trigger: true labels: - regression - operators - regression-operators - ro tf_extra_params: test: fmf: name: regression-operators ...This new configuration option allows users to utilize a new flow. When a pull request is opened (for example in draft mode), users push new commits and fixes, or when they are about to finish the pull request, they can easily type /packit test as a pull request comment and all jobs defined in packit.yaml for pull request will be triggered.
Labeling and identifyingThe above solution is very easy to use. There might be use cases, however, where users don’t want to trigger all the jobs. For example, when you have 10 jobs defined with different test scopes, you probably don’t want to trigger acceptance and regression tests at the same time since acceptance could be a subset of regression.
There are now two options to trigger a specific job. The first one is to trigger the job based on an identifier. If the user specifies identifier: test-1 in the job configuration, Packit comment command for execution of the tests will look like this /packit test –identifier test1. This command will execute jobs with the specific identifier (test-1) and nothing else.
The second option for triggering specific jobs allows you to execute more than one job based on their identifiers. You can use multiple identifiers in a comma-separated list but it might be cumbersome to specify long lists of identifiers every time. To add a better user experience we’ve introduced the labels configuration that allows grouping together multiple jobs. The command /packit test –labels upgrade,regression will trigger all jobs that contain upgrade or regression in the list of labels in the job configuration.
ConclusionIf you hesitated to utilize Packit due to the limitation of missing manual triggering of the jobs or missing labeling, you can start now! As mentioned, Packit is an open-source service and these improvements were done as contributions from outside of the Packit team, everyone can contribute so if you are missing some features, feel free to open a pull request!
For more information about newly added options you should check the documentation. In case you are new to Packit you can also view the talk from the Packit team from DevConf 2023 or DevConf Mini 2023.
Fedora Linux editions part 4: Alt Downloads
Fedora Alt Downloads is a remarkable resource provided by the Fedora Project, offering alternative distribution options for users seeking specific requirements or unique use cases. This article will delve into the diverse selection of Fedora Alt Downloads, highlighting their significance and how they cater to different needs within the Fedora community. You can find an overview of all the Fedora Linux variants in my previous article Introduce the different Fedora Linux editions.
Network InstallerThe Fedora Network Installer is an efficient and flexible tool for installing Fedora Linux. This is Fedora’s online installer. Unlike the baked-in Live images that the main editions use, this installer allows you to customize which software packages will be installed at installation time. However, because the packages to be installed are not baked into this installer image, network access will be required at installation time to download the selected packages.
Don’t confuse this with network booting which is a method of initiating an operating system or operating system installer from a small Preboot Execution Environment. (Though it is possible for that sort of bootloader to chain-load Fedora’s network installer.)
Torrent DownlodsFedora Torrent Downloads utilize the BitTorrent protocol, which is a peer-to-peer file sharing protocol. Instead of relying on a central server for downloads, BitTorrent enables users to download Fedora Linux images from multiple sources simultaneously. This decentralized approach enhances download speeds and reduces strain on individual servers, resulting in a faster and more reliable download experience. Fedora Torrent Downloads offer a fast, reliable, and community-driven method for obtaining Fedora Linux images. By harnessing the power of the BitTorrent protocol, Fedora leverages the collective bandwidth and resources of users worldwide, resulting in faster downloads and improved reliability.
Details are available at this link: https://torrent.fedoraproject.org/
Alternate ArchitecturesFedora Alternate Architectures is an initiative by the Fedora Project that aims to expand the compatibility of the Fedora Linux operating systems by offering a range of architecture options. In addition to the standard x86_64 architecture, Fedora Alternate Architectures provides support for alternative architectures, including ARM AArch64, Power, and s390x. This initiative allows you to select the architecture that best suits their hardware requirements, enabling Fedora Linux to run on a diverse range of devices and systems. Whether you have a Raspberry Pi, a server with Power processors, or other specialized hardware, Fedora Alternate Architectures ensures that you have a tailored Fedora Linux experience that meets your specific needs.
Details are available at this link: https://alt.fedoraproject.org/alt/
Fedora CloudAfter I wrote my initial post in this series that introduced the main Fedora Linux editions, Fedora Cloud was restored to full edition status. There are still some links to the Fedora Cloud images on the Fedora Alt Downloads page. But they will be removed soon. The correct place to get the latest Fedora Cloud images is now https://fedoraproject.org/cloud/download/.
Fedora Cloud images are a collection of images provided by the Fedora Project for use in cloud environments. Fedora Cloud images are specifically designed to run applications in the cloud with efficiency and optimal performance. By using Fedora Cloud images, you can quickly deploy and run applications in the cloud without the need to spend time configuring the operating system from scratch. Fedora Cloud images also provide flexibility in terms of scalability, allowing you to easily adjust the size and capacity of resources according to the needs of your applications.
Testing ImagesFedora Testing Images are a collection of specialized system images designed for testing and contributing to the development of Fedora Linux. These images allow you to test the latest features, explore the recent changes in Fedora Linux, and report any issues encountered. By using Fedora Testing Images, you can actively participate in the development of Fedora Linux by providing valuable feedback and contributions.
Your participation in testing and contributing to Fedora Testing Images plays a vital role in maintaining and improving the quality and reliability of Fedora Linux. By reporting issues, testing software, and providing feedback, you can assist Fedora developers in fixing bugs, enhancing performance, and identifying areas for further improvement and development. Fedora Testing Images provide an easy and secure way for you to engage directly in the development of Fedora Linux, strengthening the community and resulting in a better and more reliable operating system for all Fedora users.
RawhideFedora Rawhide is the development branch of the Fedora Linux operating system. It provides a continuously evolving and cutting-edge version of the Fedora Linux OS. It serves as a testing ground for new features, enhancements, and software updates that are targeted for inclusion in future stable releases of Fedora Linux. Fedora Rawhide offers early access to the latest software packages, allowing users to stay at the forefront of technology and contribute to the testing and refinement of Fedora Linux.
Using Fedora Rawhide comes with both benefits and considerations. On one hand, it provides a platform for early adopters, developers, and contributors to test and provide feedback on upcoming features and changes. This helps identify and address issues before they are included in stable releases. On the other hand, since Fedora Rawhide is constantly under development, it may encounter bugs, instability, and compatibility issues. Therefore, it is recommended only for experienced users who are comfortable with troubleshooting and actively contributing to the Fedora community.
Details are available at this link: https://docs.fedoraproject.org/en-US/releases/rawhide/
ConclusionFedora Alt Downloads provides an impressive array of alternative distributions, catering to diverse needs within the Fedora community. Whether it’s through Fedora Spins, Fedora Labs, Fedora Remixes, Fedora Silverblue, or ARM editions, users can find specialized distributions that suit their requirements, preferences, and use cases. This versatility and community-driven approach makes Fedora Alt Downloads a valuable resource for Fedora Linux enthusiasts, fostering innovation, and customization within the Fedora ecosystem. You can find complete information about Fedora Alt Downloads at https://alt.fedoraproject.org/
Contribute at the Fedora Linux Test Week for Kernel 6.4
The kernel team is working on final integration for Linux kernel 6.4. This version was just recently released, and will arrive soon in Fedora Linux. As a result, the Fedora Linux kernel and QA teams have organized a test week from Sunday, July 09, 2023 to Sunday, July 16, 2023. The wiki page in this article contains links to the test images you’ll need to participate. Please continue reading for details.
How does a test week work?A test week is an event where anyone can help ensure changes in Fedora Linux work well in an upcoming release. Fedora community members often participate, and the public is welcome at these events. If you’ve never contributed before, this is a perfect way to get started.
To contribute, you only need to be able to do the following things:
- Download test materials, which include some large files
- Read and follow directions step by step
The wiki page for the kernel test day has a lot of good information on what and how to test. After you’ve done some testing, you can log your results in the test day web application. If you’re available on or around the days of the event, please do some testing and report your results. We have a document which provides all the necessary steps.
Happy testing, and we hope to see you on one of the test days.
How to use Testing Farm outside of RHEL
Continuous integration in public projects is widely used. But it has limitations such as the size of the resources and the execution time. For instance, when you use GitHub actions free tier, you are limited to agents with 2cpu and 7GiB of memory and a total execution time of 2000 minutes per month. Similar limitations are used by other CI providers like Azure Pipelines or Travis CI. The mentioned CI systems are popular. But for some use cases, free tier is not enough. Fortunately, for community projects which are maintained or co-maintained by Red Hat or Fedora/CentOS projects, there is Testing Farm.
Testing FarmTesting Farm is an open-source testing system offered as a service. Users can use Testing Farm in many ways — use CLI from the user’s local machine to create a machine for running the tests, integrate it into the project as a CI check via GitHub Actions or Packit, or just send HTTP requests to the service API with desired requirements.
The tests are defined via tmt — Test Management Tool — that allows users to manage and execute tests in different environments. In case you are interested in more details about how Fedora manages the testing via tmt check the Fedora CI documentation.
This blog post will focus on how to use Testing Farm with projects that have tests written and managed in different testing frameworks like JUnit.
Strimzi e2e testsAs a reference project we use strimzi-kafka-operator and its test suite. Test suite is written in Java and uses the Junit5 test framework. As an execution environment it requires a Kubernetes platform like OpenShift, Minikube, EKS, or similar. Due to these requirements it is not easy to run the tests with the full potential of parallel tests execution on Azure (used as the main CI tool in Strimzi organization).
How to onboard Get the secretAs the first step, you need to get access to the Testing Farm API. To achieve that you should follow the onboarding guide which is a part of the official documentation. This secret is specific to the user and is used for authentication and authorization to the service.
Add tmt to your projectEven if users don’t use tmt for test case management, there are several parts to implement in the project to make Testing Farm understand your needs.
At first, you have to mark the root folder in your project with the .fmf directory, this can be done by using the tmt init command. For more details you can check our configuration in the Strimzi repository.
PlanPlan for Testing Farm contains a test plan definition. This definition is composed of hardware requirements, preparation steps for creating a VM executor and specific plans. Specific plan defines selectors for tests that should be executed. As part of preparation steps we also spin-up the Minikube cluster and build and push Strimzi container images used during testing. On the bottom of the file we specify specific test plan names and its configuration for executions of specific tests defined later in this article.
You can see an example of our plan below.
# TMT test plan definition # https://tmt.readthedocs.io/en/latest/overview.html # Baseline common for all test plans ########################################################### summary: Strimzi test suite discover: how: fmf # Required HW provision: hardware: memory: ">= 24 GiB" cpu: processors: ">= 8" # Install required packages and scripts for running strimzi suite prepare: - name: Install packages how: install package: - wget - java-17-openjdk-devel - xz - make - git - zip - coreutils ... ommited - name: Build strimzi images how: shell script: | # build images eval $(minikube docker-env) ARCH=$(uname -m) if [[ ${ARCH} == "aarch64" ]]; then export DOCKER_BUILD_ARGS="--platform linux/arm64 --build-arg TARGETPLATFORM=linux/arm64" fi export MVN_ARGS="-B -DskipTests -Dmaven.javadoc.skip=true --no-transfer-progress" export DOCKER_REGISTRY="localhost:5000" export DOCKER_ORG="strimzi" export DOCKER_TAG="test" make java_install make docker_build make docker_tag make docker_push # Discover tmt defined tests in tests/ folder execute: how: tmt # Post install step to copy logs finish: how: shell script: ./systemtest/tmt/scripts/copy-logs.sh ########################################################### /smoke: summary: Run smoke strimzi test suite discover+: test: - smoke /regression-operators: summary: Run regression strimzi test suite discover+: test: - regression-operators /regression-components: summary: Run regression strimzi test suite discover+: test: - regression-components /kraft-operators: summary: Run regression kraft strimzi test suite discover+: test: - kraft-operators /kraft-components: summary: Run regression kraft strimzi test suite discover+: test: - kraft-components /upgrade: summary: Run upgrade strimzi test suite provision: hardware: memory: ">= 8 GiB" cpu: processors: ">= 4" discover+: test: - upgradeTo see the full version check our repository.
TestsAs a next step we need to say how to execute tests. We created a simple shell script which just calls maven command to execute Strimzi test suite. We also defined metadata for tests which specify environment variables for test suites and also other configuration like timeout, end others.
In this test metadata example you can see that we specify default env variables and configuration and specific tests override this configuration.
test: ./test.sh duration: 2h environment: DOCKER_ORG: "strimzi" DOCKER_TAG: "test" TEST_LOG_DIR: "systemtest/target/logs" TESTS: "" TEST_GROUPS: "" EXCLUDED_TEST_GROUPS: "loadbalancer" CLUSTER_OPERATOR_INSTALLTYPE: bundle adjust: - environment+: EXCLUDED_TEST_GROUPS: "loadbalancer,arm64unsupported" when: arch == aarch64, arm64 /smoke: summary: Run smoke strimzi test suite tag: [smoke] duration: 20m tier: 1 environment+: TEST_PROFILE: smoke /upgrade: summary: Run upgrade strimzi test suite tag: [strimzi, kafka, upgrade] duration: 5h tier: 2 environment+: TEST_PROFILE: upgrade /regression-operators: summary: Run regression strimzi test suite tag: [strimzi, kafka, regression, operators] duration: 10h tier: 2 environment+: TEST_PROFILE: operators /regression-components: summary: Run regression strimzi test suite tag: [strimzi, kafka, regression, components] duration: 12h tier: 2 environment+: TEST_PROFILE: components /kraft-operators: summary: Run regression kraft strimzi test suite tag: [strimzi, kafka, kraft, operators] duration: 8h tier: 2 environment+: TEST_PROFILE: operators STRIMZI_FEATURE_GATES: "+UseKRaft,+StableConnectIdentities" /kraft-components: summary: Run regression kraft strimzi test suite tag: [strimzi, kafka, kraft, components] duration: 8h tier: 2 environment+: TEST_PROFILE: components STRIMZI_FEATURE_GATES: "+UseKRaft,+StableConnectIdentities" Run Testing Farm from command lineFinally, we can try our changes via cmd. We need to have the Testing Farm CLI tool installed and also API token. To install Testing Farm CLI follow this guide.
For example, we can run a smoke test on fedora-38 with both architectures, which means x86_64 and aarch64 just by one command.
$ testing-farm request --compose Fedora-38 --git-url https://github.com/strimzi/strimzi-kafka-operator.git --git-ref main --arch x86_64,aarch64 --plan smokeUsing Postfix DNS SRV record resolution feature
In March 2011 Apple Inc. proposed RFC 6186 that describes how domain name system service (DNS SRV) records should be used for locating email submission and accessing services. The design presented in the RFC is now supported by Postfix since version 3.8.0. With the new functionality, you can now use DNS SRV records for load distribution and auto-configuration.
What does the DNS SRV record look likeThe DNS SRV records were defined in RFC 2782 and are specified in zone files and contain the service name, transport protocol specification, priority, weight, port, and the host that provides the service.
_submission._tcp SRV 5 10 50 bruce.my-domain.com.
FieldValueMeaningservice namesubmissionservice is named submissiontransport protocol specificationtcpservice is using TCPpriority5servers priority is 5 (lower gets tried first)weight10portion of load the server should handleport50port where server listens for connectionstargetbruce.my-domain.com.name of server providing this serviceRecord explanation Server selection algorithmClients should implement the resolution of SRV records as described in RFC 2782. That means, first contact the server with the highest priority (lowest priority field value). If the server does not respond, try to contact the next server with either the same or lower priority (higher priority field value). If there are multiple servers with the same priority, choose one randomly, but ensure the probability of choosing records conforms to the equation:
where i is the identification of SRV record and k is the count of SRV records with the same priority.
In practice, this means that if you have two servers and one is 3 times as powerful as the other one, then you should give the first weight a value 3 times higher than the other one. This ensures the more powerful server will receive ~75% of client requests and the other one ~25%.
These principles allow SRV records to work as tools to both autoconfigure clients and distribute the workload among servers.
Consider the following example of such a set of records:
_submission._tcp SRV 0 0 2525 server-one _submission._tcp SRV 1 75 2625 server-two _submission._tcp SRV 1 25 2625 server-threeHere server-one would always be contacted first. If server-one does not respond, the client will shuffle the two remaining records with priority 1, generate a random number from 0 to 100 and if the running sum of the first record is greater or equal, then try to contact it. Otherwise, the client contacts the servers in reverse order. Note that the client submits the request to the first server it successfully connects to.
Configuration exampleConsider the following situation. You want to configure Postfix to relay outgoing emails through a company mail server by using SRV records for a large number of computers. To achieve this, you can configure the relayhost parameter in Postfix, which acts as a Mail User Agent (MUA) for each computer. If you set the value of the relayhost parameter to $mydomain, your machines start to look up MX records for your domain and attempt to submit mail in the order based on their priorities. While this approach works, you can encounter a problem with load balancing. Postfix uses the server with the highest priority until it becomes unresponsive and only then contacts any secondary servers. Additionally, if your environment uses dynamically assigned ports, you are not able to notify the clients what port is a particular server using. With SRV records, you can address these challenges and keep the servers running smoothly without peaks while changing the server’s port as needed.
Zone fileTo configure a DNS server to provide information to clients, see the following example zone file with servers one, two and three configured as relays and server four for receiving test mail.
$TTL 3600 @ IN SOA example-domain.com. root.example-domain.com. ( 1571655122 ; Serial number of zone file 1200 ; Refresh time 180 ; Retry time in case of problem 1209600 ; Expiry time 10800 ) ; Maximum caching time in case of failed lookups ; IN NS ns1 IN A 192.168.2.0 ; ns1 IN A 192.168.2.2 server-one IN A 192.168.2.4 server-two IN A 192.168.2.5 server-three IN A 192.168.2.6 server-four IN A 192.168.2.7 _submission._tcp SRV 0 0 2525 server-one _submission._tcp SRV 1 50 2625 server-two _submission._tcp SRV 1 50 2625 server-three @ MX 0 server-four Postfix MUA configurationConfigure client machines to look for SRV records:
use_srv_lookup = submission relayhost = example-domain.com:submissionWith this configuration, Postfix instances on your client machines contact the DNS server for the example-domain and request the SRV records for mail submission. In this example, server-one has the highest priority and Postfix tries it first. Postfix then randomly selects one of the two remaining servers to try. The configuration ensures that server one will be contacted first approximately 50% of the time. Note that the weight value in the SRV records does not correspond with the percentage. You can achieve the same goal with the values 1 and 1.
Postfix also has the information that server-one listens on port 2525 and server-two on port 2625. If you are caching retrieved DNS records and you change the SRV records dynamically, it is important to set a low time to live (TTL) for your records.
Complete setupYou can try this configuration with podman and compose file included here:
$ git clone https://github.com/TomasKorbar/srv_article $ cd srv_article/environment $ podman-compose up $ podman exec -it article_client /bin/bash root@client # ./senddummy.sh root@client # exitAfter completing the configuration steps, you can check the logs to monitor, that the mail passes server one and is delivered to server four.
$ podman stop article_server1 $ podman exec -it article_client /bin/bash root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # exitNow that the first server is down, these six mails will be relayed by either server two or three.
Take a closer look at the Dockerfiles to understand the configuration more deeply.
Finish working with the example by executing: $ podman-compose down
More in Tux Machines
- Highlights
- Front Page
- Latest Headlines
- Archive
- Recent comments
- All-Time Popular Stories
- Hot Topics
- New Members
digiKam 7.7.0 is released
After three months of active maintenance and another bug triage, the digiKam team is proud to present version 7.7.0 of its open source digital photo manager. See below the list of most important features coming with this release.
|
Dilution and Misuse of the "Linux" Brand
|
Samsung, Red Hat to Work on Linux Drivers for Future Tech
The metaverse is expected to uproot system design as we know it, and Samsung is one of many hardware vendors re-imagining data center infrastructure in preparation for a parallel 3D world.
Samsung is working on new memory technologies that provide faster bandwidth inside hardware for data to travel between CPUs, storage and other computing resources. The company also announced it was partnering with Red Hat to ensure these technologies have Linux compatibility.
|
today's howtos
|




.svg_.png)
 Content (where original) is available under CC-BY-SA, copyrighted by original author/s.
Content (where original) is available under CC-BY-SA, copyrighted by original author/s.

{kind=link}
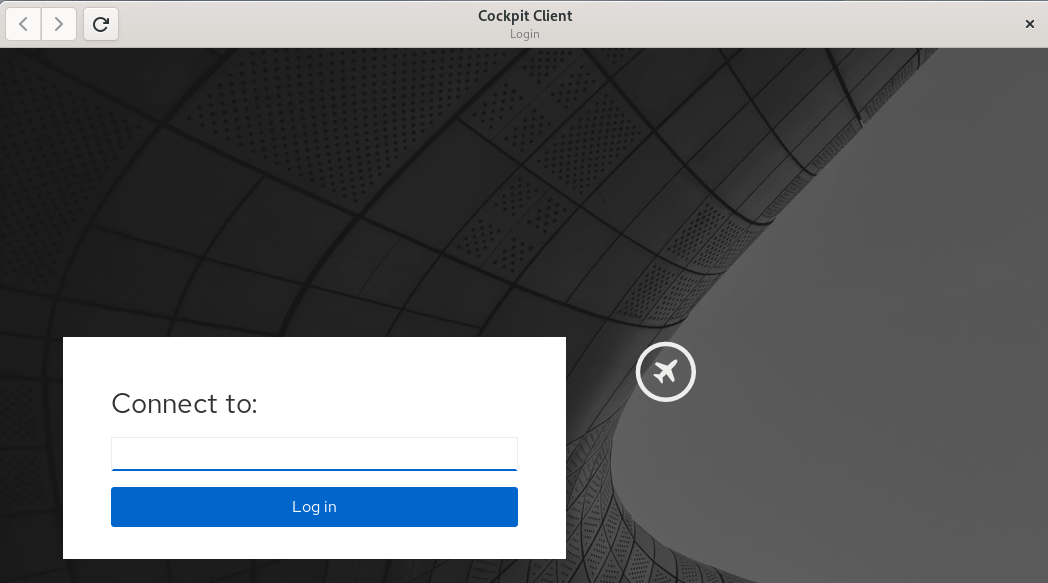{kind=link}
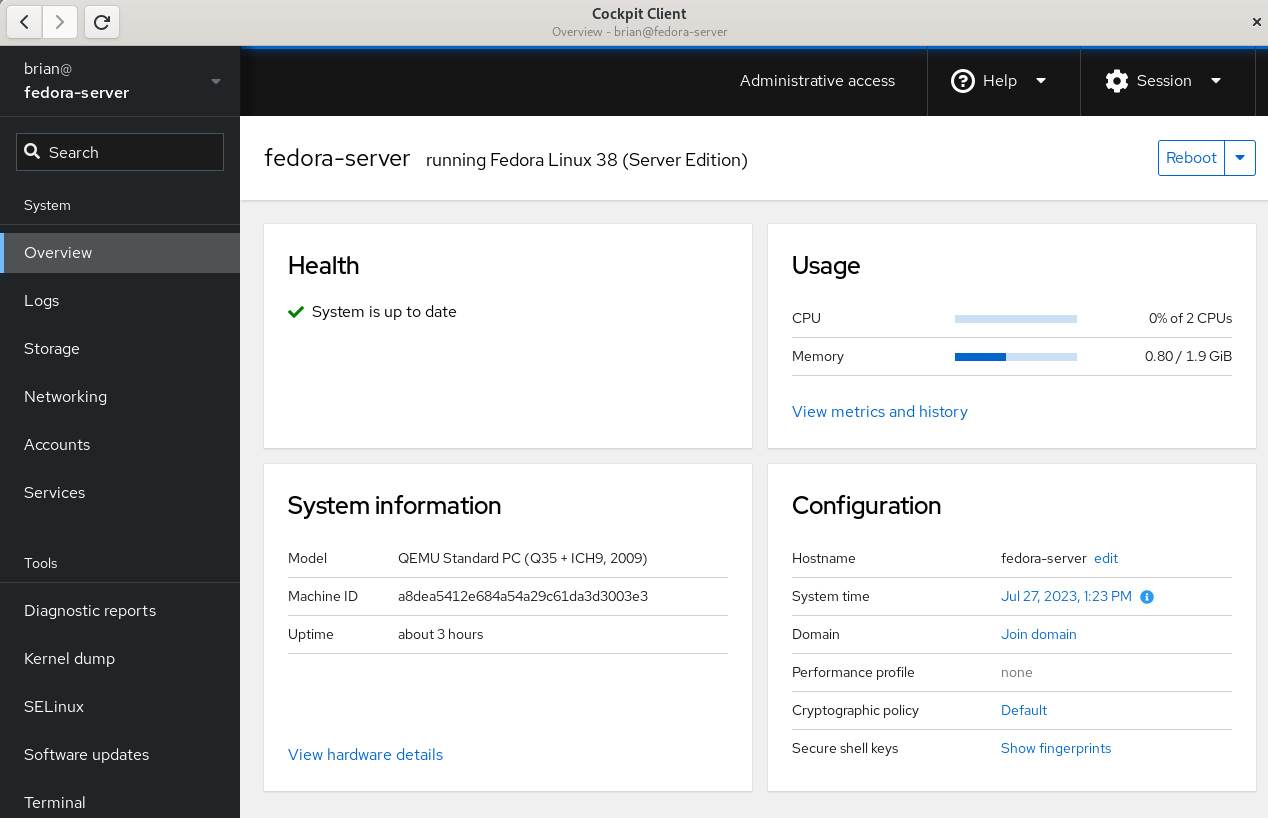{kind=link}
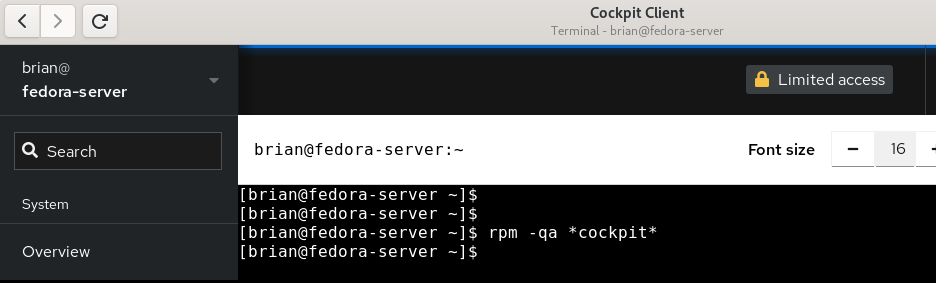{kind=link}
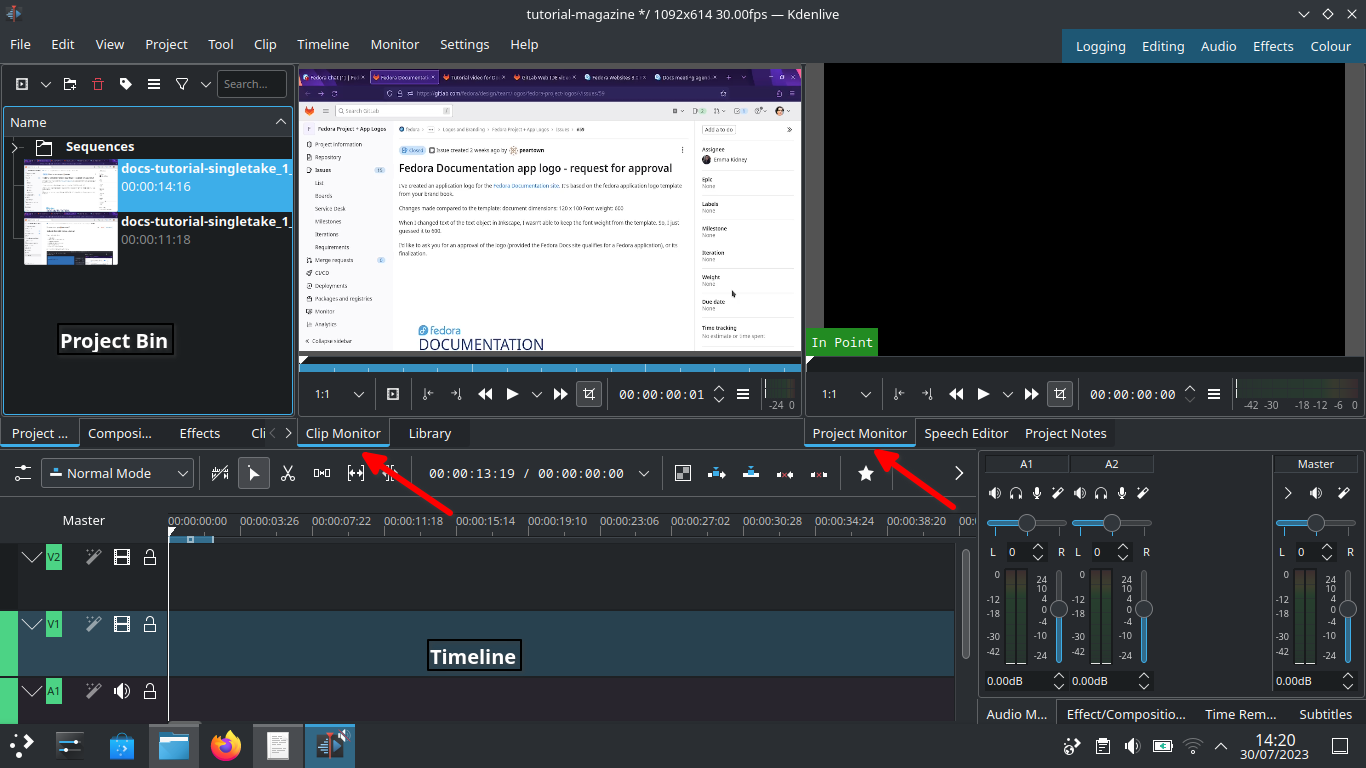{kind=link}
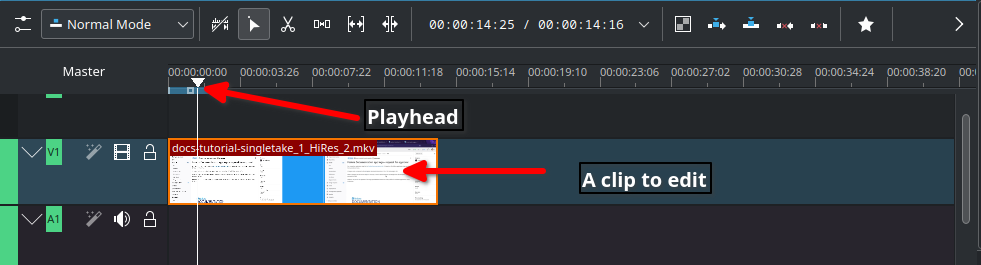{kind=link}
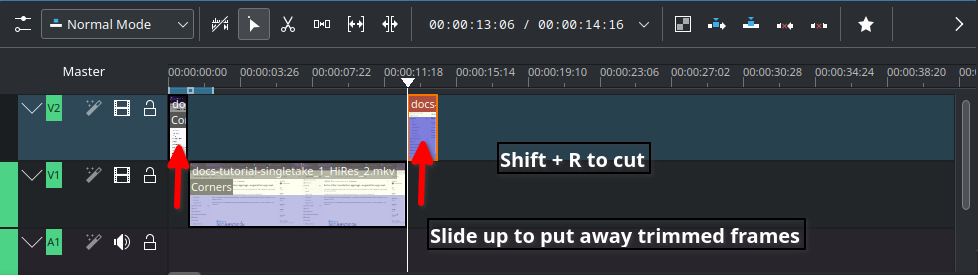{kind=link}
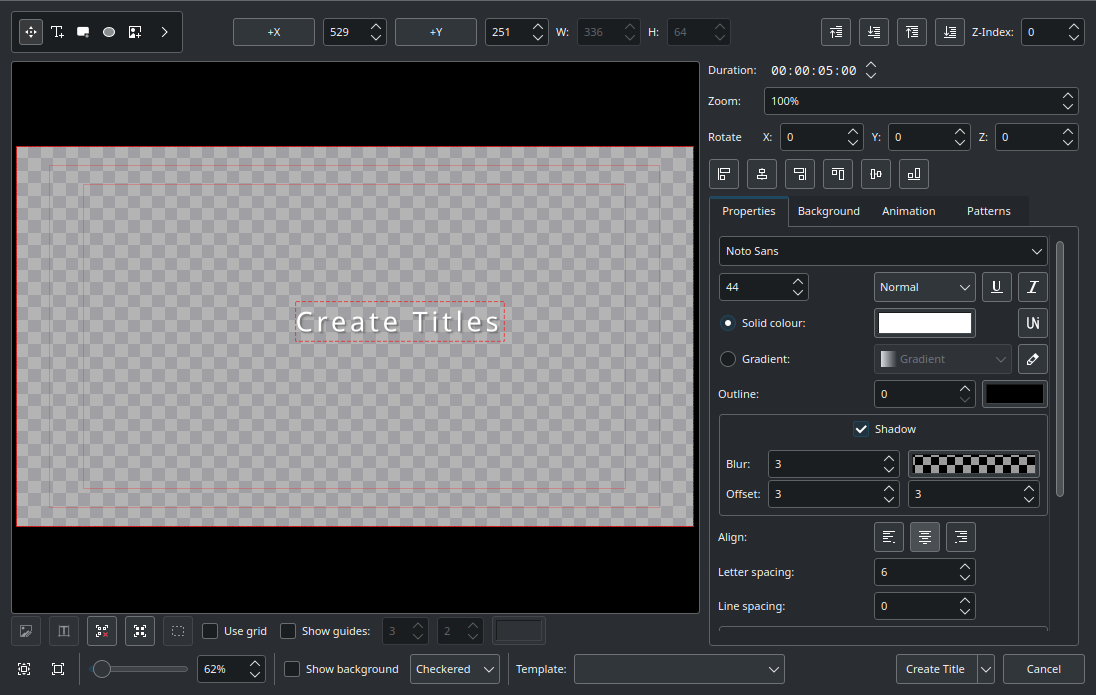{kind=link}
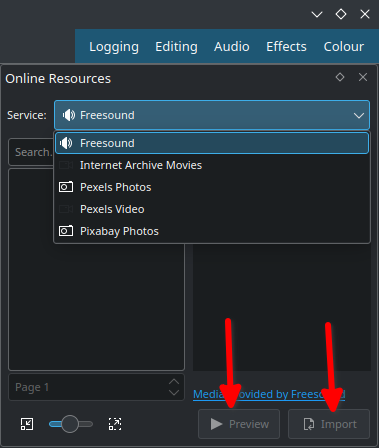{kind=link}
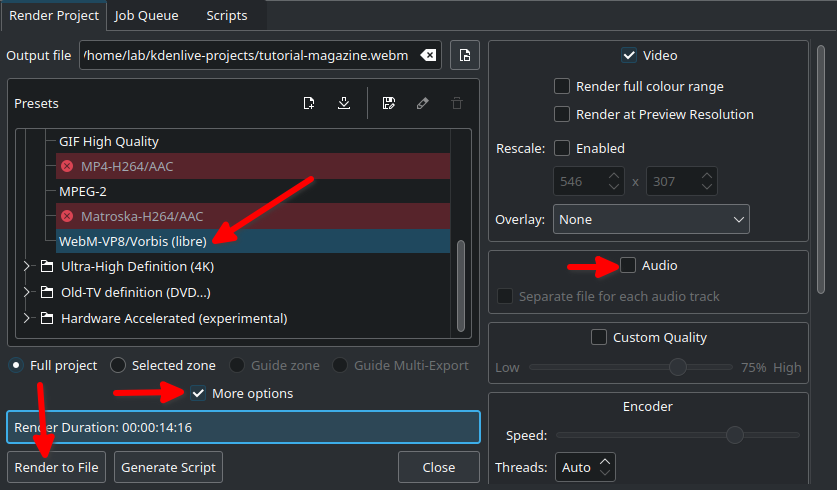{kind=link}
{kind=link}
{kind=link}
Recent comments
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago
1 year 12 weeks ago